AutoML
paper:AutoML综述
Taking Human out of learning application: a survey on automated machine learning
- Feature engineering
- model selection
- optimization algorithm selection
Optimizer & Controller
- For Optimizer:
- Simple search approaches: Greedy search, random search
- Optimization from samples
- Heuristic search
- Model based Derivative-Free Optimization
- RL
- Gradient descent
- Greedy search
- For evaluator
- Direct evaluator
- sub-sampling
- early stop
- parameter reusing
- surrogate evaluator
- Experienced techniques
- Meta Learning
- Transfer Learning
NAS
paper: Neural Architecture Search with Reinforcement learning
搜索空间
网络结构和超参数
搜索策略
使用怎样的算法可以快速、准确找到最优的网络结构参数配置
- RL:controller为RNN,PG
- 进化算法
- 贝叶斯优化
评价预估
利用controller生成rnn
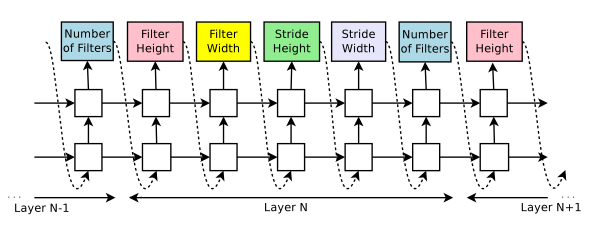
如果层数超过特定值,则controller生成model将停止
在收敛时,记录validation accuracy
并行训练 加速更新
一共有S个 Parameter Server用于存储 K个 Controller Replica的共享参数。然后每个 Controller Replica 生成m个并行训练的自网络。controller会根据m个子网络结构在收敛时得到的结果收集得到梯度值,然后为了更新所有 Controller Replica,会把梯度值传递给 Parameter Server。
Skip connection
使用基于attention的skip connections或branch layers来扩大搜索空间
在每一层,anchor point有N-1个sigmoids,以指示需要连接的previous layer
生成RNN cell:
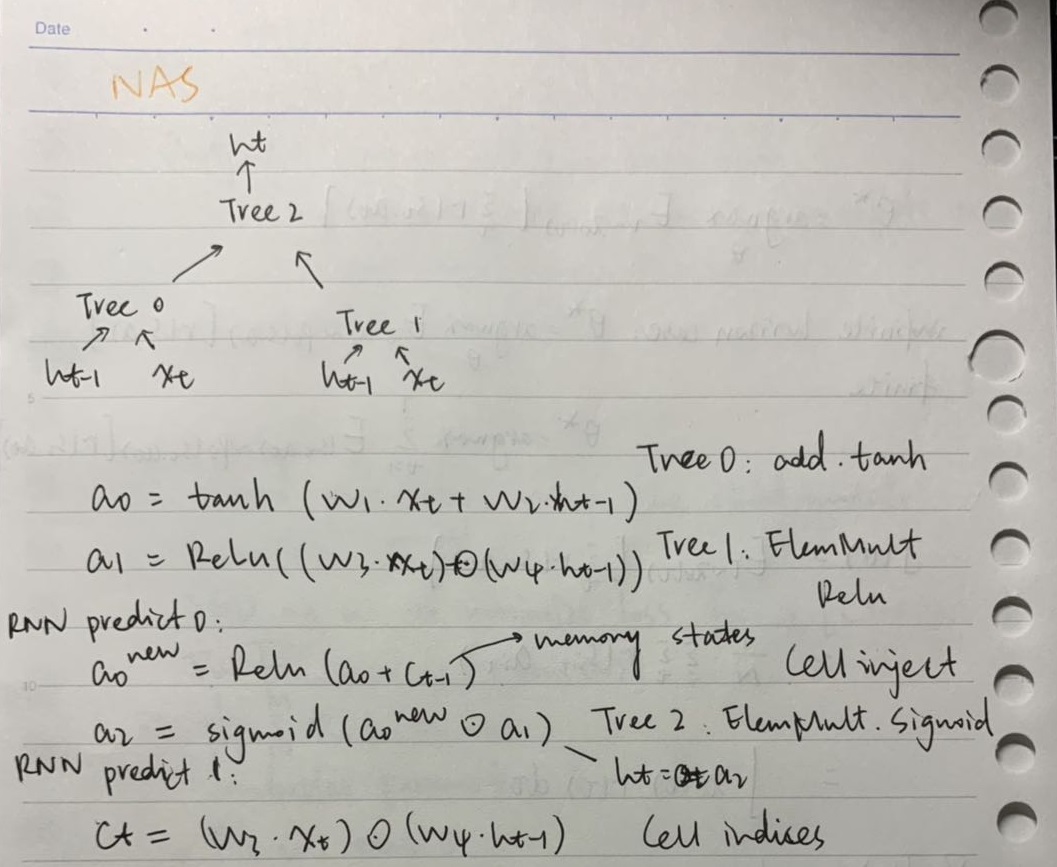
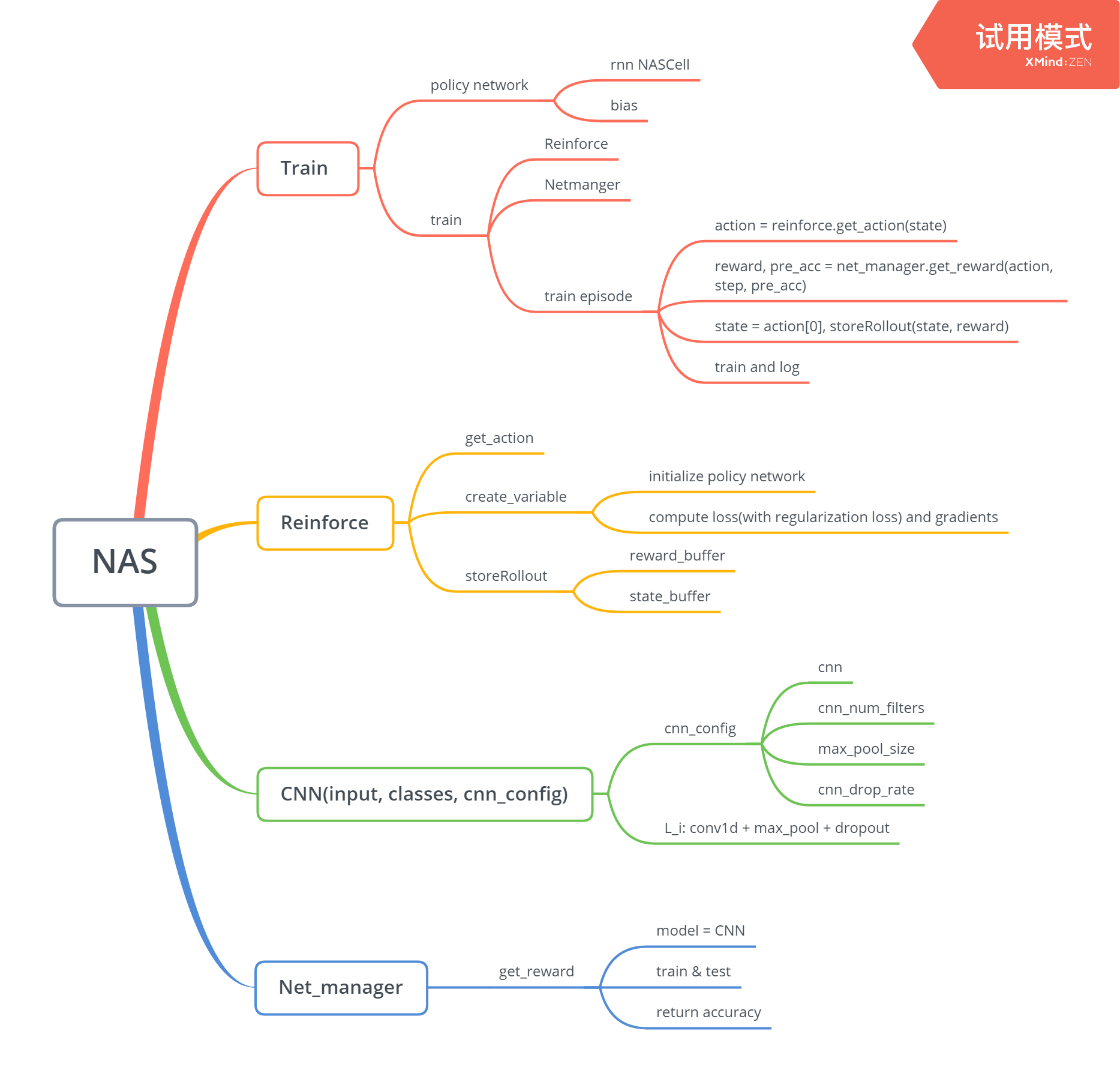
代码分析:
NAS局限性:
NAS的搜索空间有很大的局限性,目前NAS算法仍然使用手工设计的结构和block,NAS仅仅是将这些block堆叠
NAS关键点:
如何能在更广的搜索空间中找到新的架构?
ENAS
paper:Efficient Neural Architecture Search via Parameter Sharing
权值共享,不同模型共享权重
引入Node,相较于layer,其有pre-node index属性,节点数固定
巧妙的node结点设置,学习和挑选node之间的连线关系,不同的连线方案会产生大量的神经网络模型结构,从中选择最优的连线方案
搜索策略
controller如何做出决策
LSTM网络
什么样的搜索策略
Marco search 宏搜索
- 决定对前面的网络层该执行什么样的操作
- 考虑用于跳跃连接的前面的网络层是哪个
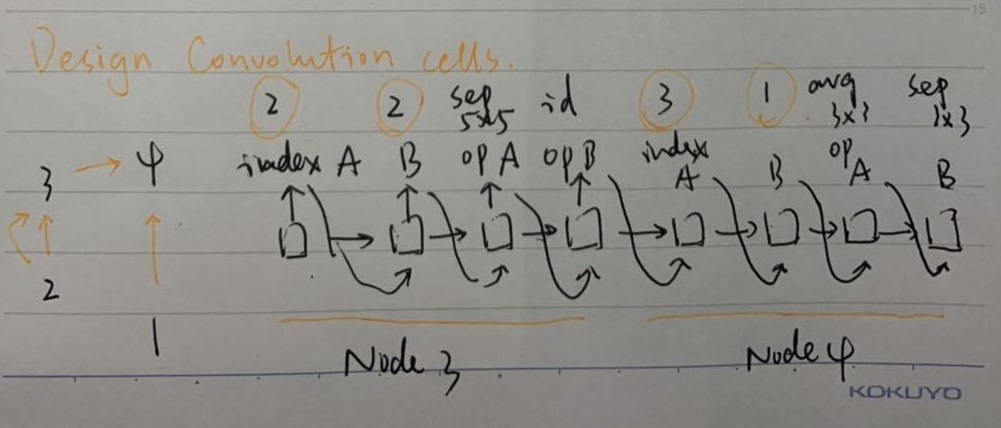
Micro search 微搜索
设计模块或者构建组件,模块或者组建联合构建最终的网络
Child model包含多个组件,每个组件包含N个conv cell和1个reduction cell,每个卷积或者下采样cell包含B个node,每个node由标准卷积操作组成
- Block
- Conv cell and reduction cell
- Node
后面的node需要decide:
- 需要连接的两个node
- 对需要连接的两个node各自执行的两个操作
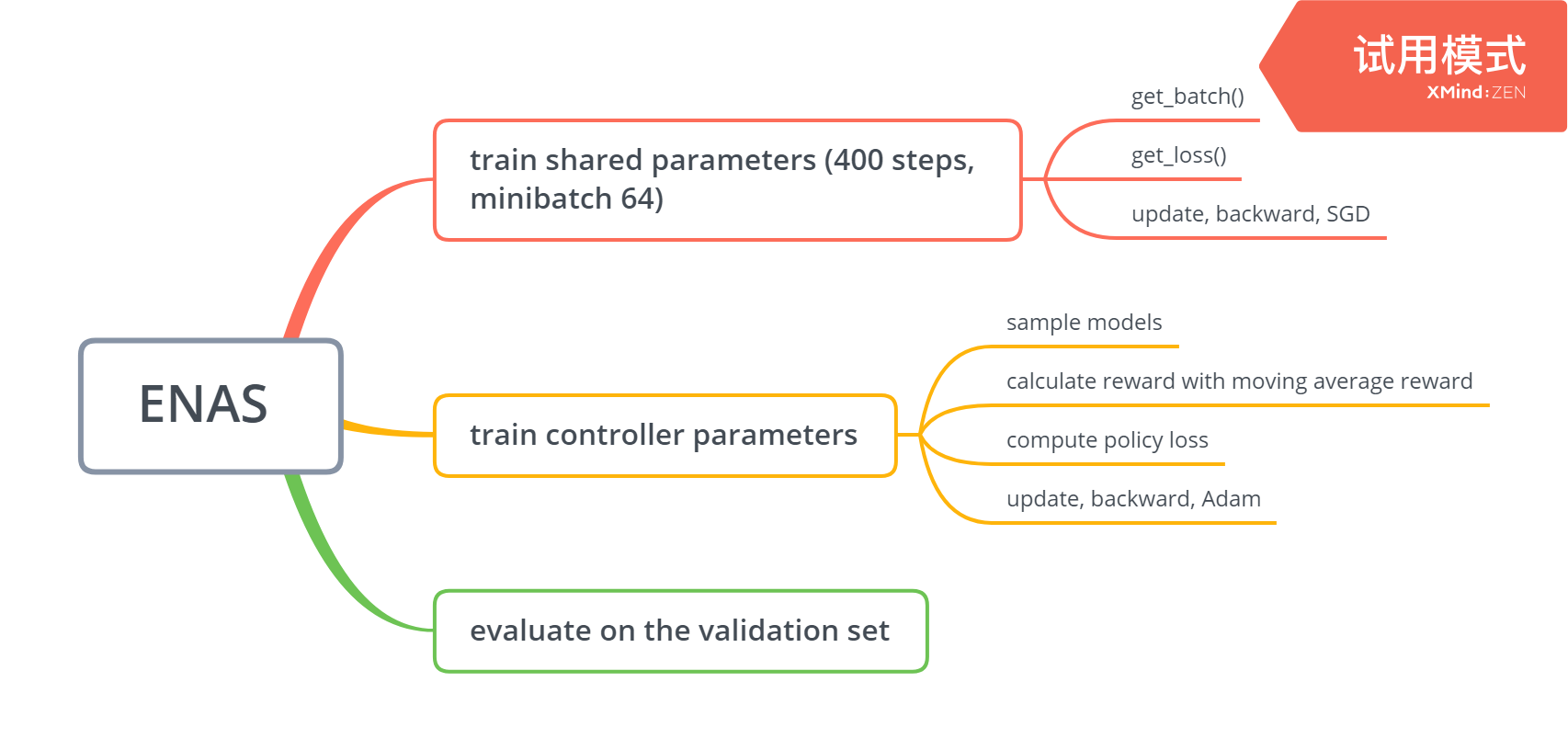
ENAS 两种神经网络:
- controller:RNN
- Child model:任务所需网络,CNN
- controller构建child model
- 使用gd训练child model until convergence
- PG update parameter of controller
RL elements:
Agent: controller
Action: policy for generate child model
Reward: val_acc for child model
|
|
DAG 数据结构:
|
|
node -1: pre-index为node 0, activation为tanh



ENAS的高效在于:
迁移学习
如果两个节点之间的计算过程之前已经完成训练,那么卷积核的权重与1*1的卷积(用来保持channel)就会被复用
局限性or改进的方案:
node结点数目一致时,可能限制模型的多样性
pre-node index,连接多个node,连接的方法
Code:
https://github.com/carpedm20/ENAS-pytorch
Also see in:
http://www.zhuanzhi.ai/document/c5f1eef032a1d89ca39715562527c533